Nearly every week, an agile team will ask me, When should we create and update our development documentation?
For example, I recently taught a class for a company that is developing a medical device and its surrounding software ecosystem. It was a diverse class that included participants from the company’s regulatory group, quality (validation and verification) group, as well as staff members from hardware, firmware, and software. The question of when to update development documents across the diverse body of work came up multiple times during the class.
This question can be answered using a model based on the economics of batch size.
To Document or Not to Document
Some people mistakenly believe that agile development shuns development documentation. They read the part of the Agile Manifesto that states “working software over comprehensive documentation” and conclude that producing development documents is anti-agile. Agile isn’t anti-documentation, agile is anti-waste.
Agile isn’t anti-documentation, agile is anti-waste.
Spending time and money to create a document that nobody will ever read or use is waste—and should be avoided. However, not every document is waste. There are certainly cases where some forms of documentation are helpful or even essential.
Returning to the medical device company example, the questions the team members asked had nothing to do with whether the documents would add value. On the contrary, the documents in question were non-negotiable. The company must create certain documents to comply with FDA regulations such as 21 CFR Part 820, or it will not be able to ship its product. So the critical question for this company is when, not if, the documentation work should take place.
Documenting in a Scrum Environment
From a Scrum perspective, if certain documents must be completed in order for the product to ship, then the creation/updating of those documents should be part of the definition of done. In other words, a product backlog item cannot be considered “done” unless the documentation has been created/updated accordingly. If teams follow this rule, the documents will be maintained each sprint alongside the shippable features.
An alternative is to perform one or more specialized documentation sprints. These typically happen near the end of the development effort, when most of the features have been created. Delaying documentation is problematic and not something I’d recommend. First, the product is not in a potentially shippable state every sprint (since it lacks required documentation). Second, deferring the work of creating and updating documents until (potentially long) after the actual work was done increases the risk that important information could be forgotten by the time the documentation is written, if it is ever written.
Deciding When to Create and Update Documents
So why do we need a model to determine when to update documents if the general advice is to update and create development documentation as a part of each sprint’s definition of done? In a word, “economics.”
Let’s return once more to the example of the medical device company. In a highly regulated environment, making changes to a document involves more overhead than in non-regulated environments. In a non-regulated environment, anyone (within reason) could open up a document and start making edits and then close the document—and the update is considered complete. Companies in non-regulated environments might have a more formal process for updating documents, but they are typically not required to have additional formality in their process.
Regulated environments are very different. For example, editing a document there could involve updating not only the target document, but also other documents to maintain appropriate traceability among the development artifacts. And, all approved documents (e.g., specifications, test procedures, user manuals, etc.) that have been affected by a change must be updated in accordance with established and verified configuration management procedures. Also, at this particular medical device company, these updates require independent verification by people who are not involved in making the documentation updates and frequently not part of the team developing the product.
In fact, there may be even more steps involved in updating documents in a regulated environment that I have not mentioned here. The point is the overhead cost (transaction cost) of updating a document is likely much higher in a regulated environment than a non-regulated environment. Because of this overhead cost in regulated environments, the economics may not favor making micro-updates to documents.
Because of this overhead cost in regulated environments, the economics may not favor making micro-updates to documents.
Instead, the economics may favor batching up some of these changes and making them at the same time. The question, then, becomes how big a batch of document updates should we hold on to before we make the update?
The question, then, becomes how big a batch of document updates should we hold on to before we make the update?
This is a classic batch-size optimization problem, where the optimal batch size is a function of the holding cost and transaction cost (see Don Reinertsen’s The Principles of Product Development Flow: Second Generation Lean Product Development).
Finding the Optimal Batch Size
Finding the optimal batch size for the documentation (or anything) is a U-curve optimization problem.
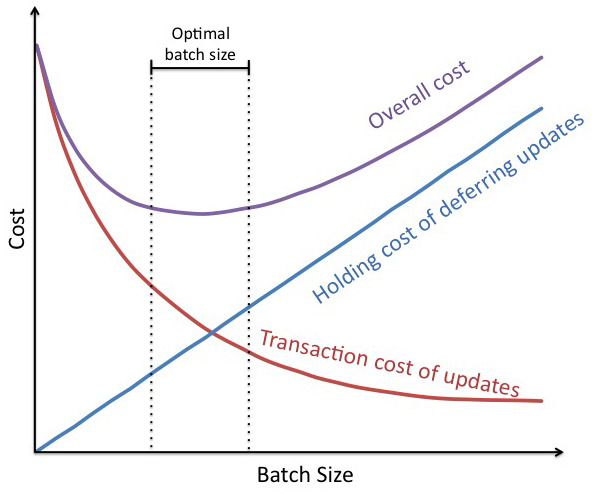
In the graph above the goal is to minimize the overall cost of making documentation updates. There are two costs that we must consider. The first is the transaction cost (red curve) of making documentation updates. The second is the holding cost (blue line) of deferring (not immediately making) the updates. By adding these two costs together we get the overall cost (purple curve) for a batch of a particular size. The optimal batch size of documentation changes can be found at the low point of the overall cost curve. Since U-curves tend to have “flat” bottoms, the optimal batch size is shown in the picture as a range, bounded by the two vertical dashed-lines.
The Intuition Behind the U-Curve Model
To getting a better feel for the intuition behind this model, use the example of sending bytes of data across the Internet. Data is sent in packets and each packet has a standard format with required fields, which themselves require a certain number of bytes. So, to send any packet of data there is a transaction cost (overhead cost) associated with the packet. If we were to send only one byte of data in each packet (the smallest possible batch size), then the transaction cost of sending the packet would be very high (we would incur the full cost of the packet header overhead to send just one byte). To amortize the transaction cost over more data, we would want to send more bytes in each packet. The question is how many bytes?
Let’s say we send 1Mb of data in each packet. That would certainly lower the transaction cost of sending each byte (i.e., one packet header for 1Mb of data as opposed to one packet header for each single byte of data). However, it would also increase the holding costs. First, we would have to maintain large buffers on both the sending and the receiving ends to store such large batches. Plus, should a transmission problem corrupt a packet, we would need to resend the entire 1Mb of data. So 1Mb of data per packet is far too large in terms of batch size.
Notice that the optimal solution is not at the extremes. Instead the optimal batch size is where the combined transaction and holding costs are minimized (in the case of Internet packets, in the 2k to 4k bytes range).
Also important, as I mentioned earlier, is that U-curve optimizations have flat bottoms, so we don’t have to be precise with our batch size, just accurate. According to Reinertsen, a 10 percent error in optimum batch size results in a 2 to 3 percent increase in total cost. So, our choice of batch size is very forgiving of errors. This is extremely helpful in an agile environment, where we frequently have to inspect and adapt ourselves to a good solution. In our documentation example, we don’t have to be precise on the number of documentation updates we include in our batch; we just have to be in the range of good sizes.
We Favor Smaller Batches
That being said, the economics for product development do tend to favor smaller batches, especially as compared to manufacturing. The U-curve picture above is based on manufacturing’s standard Economic Order Quantity (EOQ) equation. In manufacturing the transaction costs tend to decrease with increasing batch size (a large fixed transaction cost is spread out over more units as batch size increases) while holding costs tend to increase linearly with batch size (the cost of deferring the work on two units is twice the cost of deferring the work on one unit). Conversely, in product development, it is very likely that transaction costs actually increase with batch size, while holding costs grow more quickly than linearly with batch size.
In other words, the U-curve shown above is likely showing a batch size range with a low end and high end that are far bigger than they should be. Or thought of another way, in product development reducing batch size (i.e., staying at the low end of the batch-size range) will likely yield much more profound benefits than it might appear from the picture above.
In Chapter 3 of my Essential Scrum book I summarize the benefits of smaller batch sizes:
- Reduced cycle time
- Reduced flow variability
- Accelerate feedback
- Lower risk of failure
- Reduced overhead
- Increased motivation and urgency
- Reduced cost and schedule growth
When we increase batch sizes we start to lose these benefits. So if we replaced the linear holding cost line with a curve that moved higher earlier and faster, and if the transaction cost curve actually started turning back up instead of leveling out low we would quickly see that optimal batch size would be even smaller than shown in the picture above. In other words, the number of document changes we should batch up will be smaller than shown in the picture.
Focus on Reducing Transaction Costs
In product development, the large holding costs will exist whenever we have large batch sizes (because of slow feedback, more variability, lower quality, etc.). Meaning, there isn’t much we could do to reduce the holding costs. So, we should focus our attention on reducing transaction costs. In our documentation example, the transaction cost is the cost of executing and verifying all of the documentation changes (e.g., creating and updating documents) that are in the batch.
This means we should streamline the overhead of making documentation updates so that it becomes more economical to process smaller batches of documentation changes. How can we do that?
Here are just a few possibilities:
- Streamline tools. For example, perhaps we use one tool to manage all of the documentation artifacts (e.g., a tool like JIRA, Rally, or VersionOne) so that changes don’t have to be made in multiple different tools (e.g., Microsoft Word).
- Change team composition. Ensure that all of the proper people are in place to review changes. In this way we won’t have to batch up documentation changes simply because we have to wait until appropriate verification personnel become available.
- Invest in infrastructure and automation. Look for ways to remove bottleneck resources from the process and reduce the risk of human error in mind-numbing, complex tasks (like maintaining traceability among artifacts).
Conclusion
Transaction cost constraints sometimes makes the agile ideal of updating documents in each sprint impractical. In those cases, teams should make documentation changes in small batches rather than save them all for one or more big “documentation sprints” at the end of the development effort.
To determine how many documentation changes we should batch and perform together, I recommend teams create a U-curve optimization model. This model uses the approximate transaction and holding costs to arrive at a range of good batch sizes. (Since U-curves have flat bottoms, we don’t need to find the precise batch size; we just need to get into the proper range.) At the same time, I encourage teams to work relentlessly to reduce those transaction costs, thus making smaller batch sizes more economically feasible.